- The Internet Archive (Wayback Machine) is a digital library for old websites and multimedia content.
- You can use the Wayback Machine to visit websites and pages that were deleted.
- You can also access older versions of a website of page using this massive Internet Archive library.

I still remember how fascinated I was by the Encarta digital encyclopedia, back then a modern library of human knowledge. It was so much cooler than a typical library (and I was a bit of a library nerd when I was a kid).
Time has passed and people rarely use libraries anymore. Why would you if you already have the entire human knowledge at your fingertips in that little computer you carry in your pocket at all times.
Well, today we don’t have a problem with access to information. We have a problem with finding the information we need or finding old information that is long gone.
This is why I got the idea of writing this article about one of the world’s biggest digital libraries, the Internet Archive (archive.org), home of a very useful utility: the Wayback Machine.
What is the Wayback Machine?
The Internet Archive stores more than 866 billing web pages. Yes, billions. And the index is growing every day.
What’s cool about the Wayback Machine is that it lets you visit websites that are no longer online and even lets you retrieve old versions of the pages found in the archive index.
Best uses for the Internet Archive
How I best use the Internet Archive: I’m not visiting old websites out of nostalgia. I have used the Wayback Machine in one important way: to add an old website I worked for in my CV portfolio section.
Some services like Cloudflare will use the huge archive index to display the latest version of a webpage when the parent website is not available, for some reason.
The archive is also a good way to get access to older content. Webmasters without a backup will surely appreciate this. It’s like a free revision/backup system that works with webpages, not documents.
How to use the Wayback Machine to access old or deleted websites and web pages
In case it’s your first time using the Wayback Machine here is how it works:
1. Go to the web archive section.
2. Use the Enter URL or keywords form at the top to search via a website URL or specific keywords.
3. After a few seconds you should see a list of websites found in the archive that correspond to your search.
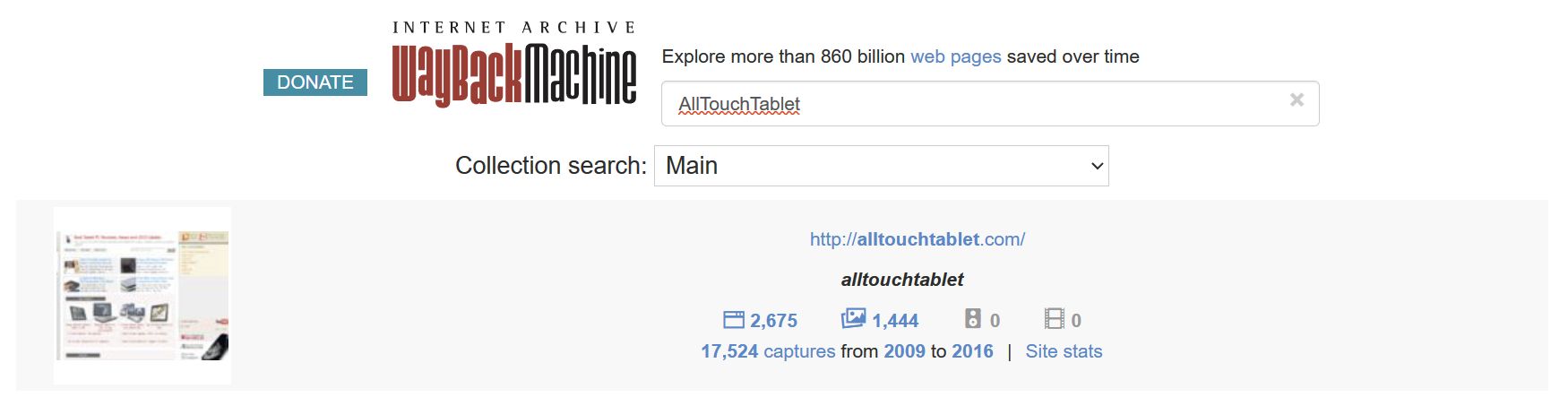
Each item in the list shows how many pages and images were indexed and how many snapshots were captured. In the image above you’ll see an example of an old website of mine, AllTouchTablet.
4. Click on the website thumbnail now to access a timeline of the entire archive with a calendar view.
Each date in the calendar with a colored dot signifies a date where snapshots were taken. A bigger dot equals more snapshots. Above the calendar there’s a scrolling timeline that lets you jump easily to another year. A graph shows you the distribution of snapshots.
Clicking each year will update the calendar view. The timeline illustrates that 2011 and 2012 were the busiest years for my website. That was when my site was more popular.

5. Clicking on a date with a snapshot will load the cached copy of that page.
On top of the snapshot, you’ll find a small bar that lets you navigate quickly to the previous or next snapshots, or jump directly to a specific date from the (smaller) timeline view.
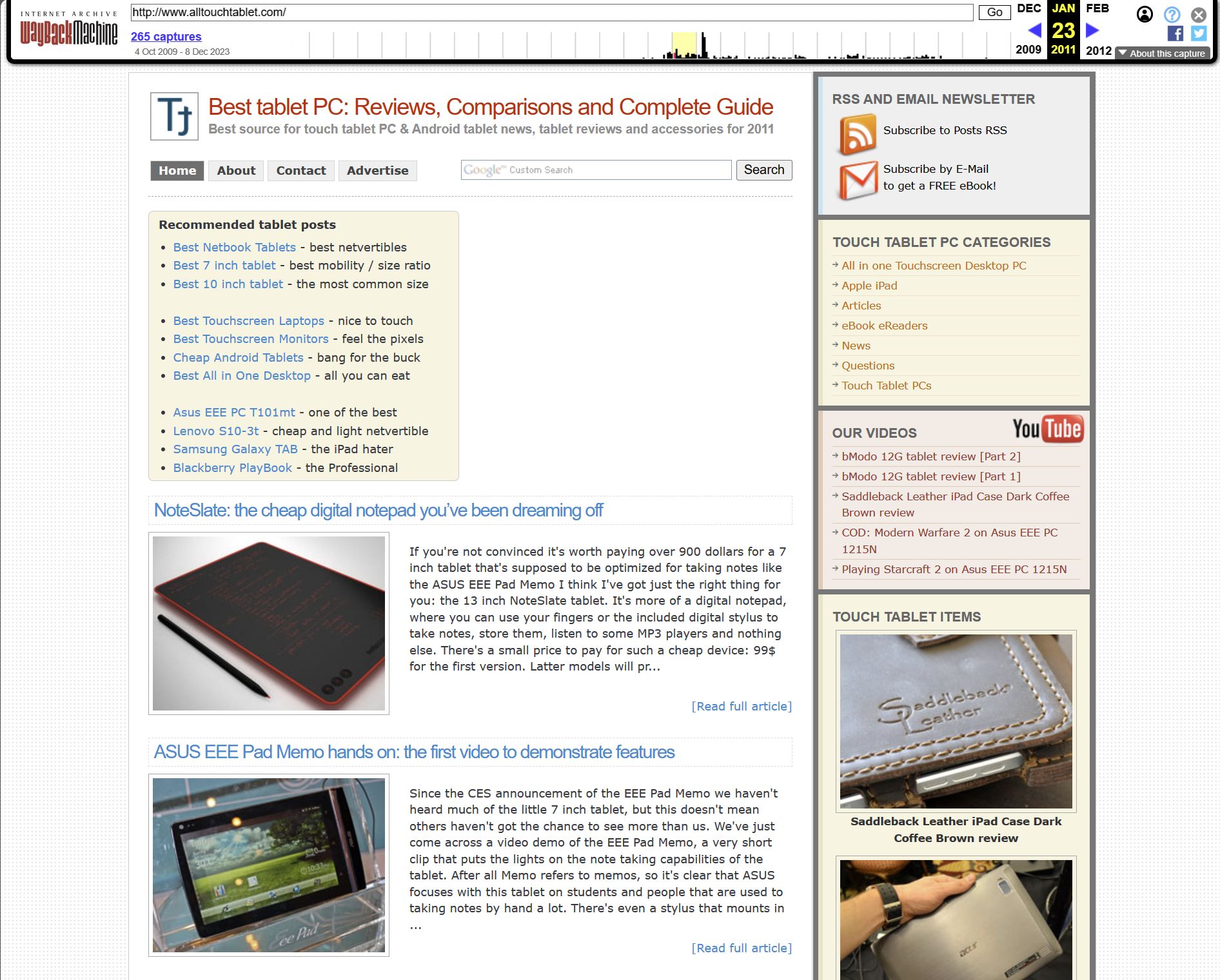
It works pretty well, and the cached copy is almost 100% identical to the original, as far as I can remember.
Limitations: you have to be aware that the Internet Archive doesn’t index full websites. You’ll most likely find an archive of the homepage and a few other important pages. It all depends on how popular a website it. Larger websites tend to have more pages indexed and more snapshots.
What else can you find in the Internet Archive?
The Wayback Machine is just a part of this archive, dealing with the world wide web.
There are gazillions of items archived by the world’s largest digital archive:
- Texts: over 40 million books and documents.
- Videos: over 12 million videos.
- Audio: over 15 million audio clips.
- TV: over 2.7 million TV news.
- Software: over 1.1 million apps.
- Images: over 4.8 million pictures.
- Concerts: over 258 thousand live concerts.
- Collections: over 2.1 million collections of items.
The Internet Archive has been saving items since its inception, back in 1996. It’s one of the things we take for granted, just like Wikipedia, but we forget how fragile these not-for-profit organizations can be. If you want to contribute to keeping the dream alive you can donate here any amount you see fit.